

ScalaItaly – Neues aus der Scala Community
Am vergangenen Wochenende fand in Florenz ein weiteres Mal die ScalaItaly Konferenz statt. An zwei aufeinanderfolgenden Tagen konnten die Teilnehmer Talks aus verschiedensten Bereichen der Softwareentwicklung rund um die Programmiersprache Scala anhören und es wurden parallel auch diverse Workshops angeboten. Alle Talks wurden aufgezeichnet und man kann sie zeitnah im Internet anschauen.
Die Keynotes
Am Freitag begann die Konferenz mit einer Keynote von Heather Miller, ehemalige Direktorin des Scala Centers und jetzt Assistenz Professorin an einer Universität in den USA für verteile Systeme. Ihre Keynote handelte von der Open Source Community und dem Trend, dass immer mehr, auch große, Firmen auf den Trend aufspringen und für Software nichts mehr bezahlen wollen. Open Source ist super und wichtig, allerdings sollten erfolgreiche Projekte in ihren und auch unseren Augen ausreichend finanziell unterstützt werden, damit der Truck Faktor nicht zum Tragen kommt und die Community mitwächst. Dieser sagt aus, wie viele Programmierer eines Projektes von einem Truck erfasst werden könnte, bevor die Community darunter schweren Schaden erleiden wird. Wer ein Open Source Framework in Erwägung zieht kann beispielsweise http://gittrends.io/ für eine Entscheidungsfindung verwenden. Dennoch steht die Bezahlung in einem Widerspruch zur Definition von Open Source und somit ist die Frage wie man eine Open Source Community monetär bestmöglich unterstützen kann nicht leicht zu klären.

Convergence of stream processing and microservices architecture
Der Samstag begann mit einem Blick in die Zukunft der Softwarearchitektur und der Entwicklung von modernen Softwaresystemen. Laut Viktor Klang, Debuty CTO von Ligthbend, rücken sich die Themengebiete der Datenanalyse und der Serviceverarbeitung immer näher zusammen. Dazu zeigte er die Historie der beiden Disziplinen auf. Bei der Datenanalyse begann er mit Offline Batches und gelangte über die Jahre hin zu modernen Streaming Systemen. Auf der Serviceseite begann er bei klassischer Client Server Architektur und kam über n-Tier Systeme hin zu modernen Microservices. In seinen Augen werden die beiden Teilbereiche in naher Zukunft konvergieren und man wird mit reaktiven Systemen beide Disziplinen mit nur einem Dienst verarbeiten und anbieten können. Am Ende ginge es schließlich in beiden Fällen immer um die Daten. Auch das Training von Machine Learning Modellen anhand von Streaming Daten in Echtzeit wird über kurz oder lang möglich sein, wenn man dem Vortrag von Uber über Data Science mit Scala Glauben schenkt. Mit akka und Scala sind Unternehmen somit sehr gut für die Zukunft aufgestellt. Eine weitere Prognose die Viktor wagte ist, dass die Services immer weiter an den Rand verlagern werden. Stichwort hier ist Edge Computing bzw. Fog Computing. Wir glauben an einen ähnlichen Trend und so haben wir uns bereits vor 2 Jahren die Domain fog-computing.de gesichert. Systeme sollten für einen bestmöglichen Einsatz mehr wie eine Pipeline gestaltet werden, die über eine Art Workflow miteinander kombiniert werden können. Ob in dieser Pipeline Daten verarbeitet und Machine Learning Modelle trainiert werden oder ob es Daten per REST an Benutzer ausliefert ist dabei dann nicht mehr wichtig. Der Gedanke des reaktiven Manifests ist hier tief verankert und es geht immer um Daten und Nachrichten.

Extend to the edges with edge and fog computing
Die Vorträge und Workshops
Die Vorträge und Workshops waren mit viel Wissen aus dem Scala Umfeld gefüllt. So gab es Workshops über sbt, über die Programmierung von Scala Entwickler Tools, über den Typelevel Stack und einen Einstieg in Apache Spark.
Bei den Vorträgen reichte der Fokus von sehr funktionalen Talks wie Kindpolymorphie bis hin zu praktischen Cloud-native nahen Vorträgen wie Kubernetes mit akka cluster. Generell waren die Talks weniger für Anfänger eher für fortgeschrittene Programmierer geeignet. Besonders spannend war ein Einblick in das Leben eines Data Scientiest bei Uber und wie Uber datengetrieben die Plattformentwicklung mit Machine Learning vorantreibt. Scala nimmt dabei mittlerweile eine immer größere Rolle ein.
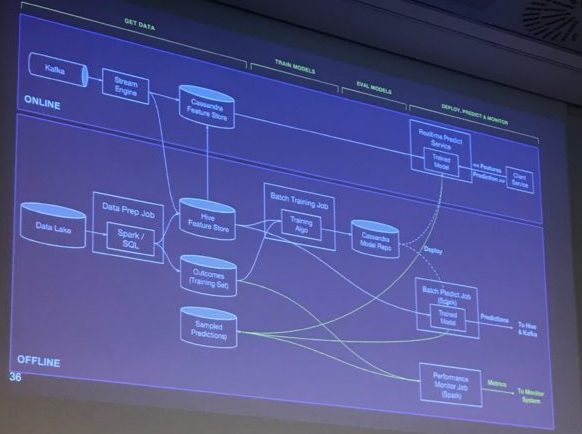
data engineering architecture at uber with spark
Zusammenfassung
Die Konferenz wurde mit einer Podiumsdiskussion abgerundet in der es viel um die Scala Community und vor allem Scala 3 (Dotty) ging. Wir können den ersten Stable Release von Scala 3 gar nicht erwarten.